── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.2 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.4
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errorsBasic Tidyverse Concepts
(All Sections)
The tidyverse “Package”
Attach It
The Pipe Operator
The Pipe
|> is from R’s package base.
Usage:
The Idea of the Pipe
The value returned by the first call becomes the first argument of the second call.
Another example:
Piping to Another Argument
Use the _ to pipe to an argument other than the first one:
Another example:
Practice
Rewrite the following call with the pipe operator, in three different ways:
The Tidyverse Pipe
The %>% Pipe
The tidyverse incorporates a pipe form the magrittr package. It looks like this: %>%.
The placeholder is indicated by the dot (.) instead of an underscore.
Example
Another Example:
Yet Another Example
But …
… we’ll mostly stick with |>.
Tibbles
Data Frames
What sort of thing is bcscr::m111survey?
Yep, it’s a data frame.
Tibbles
Tibbles are similar to data frames. You can always turn a data frame into a tibble:
Conveniences
The printout is compact:
This is an advantage when you are dealing with large amount of data.
Subsetting with dplyr
The dplyr package is part of the tidyverse. It contains function to manipulate data sets.
Pick Out Rows With filter()
Pick Out Columns With select()
Chaining
filter() and select() are examples of data verbs: they operate on data tables.
A data verb:
- takes a data table (data frame, tibble, etc.) as its first argument;
- returns a data table.
Hence they may be composed easily.
Example of Chaining
Leaving Columns Out
Put - signs in front of the columns you don’t want:
Transforming Variables With mutate()
Classify Drivers
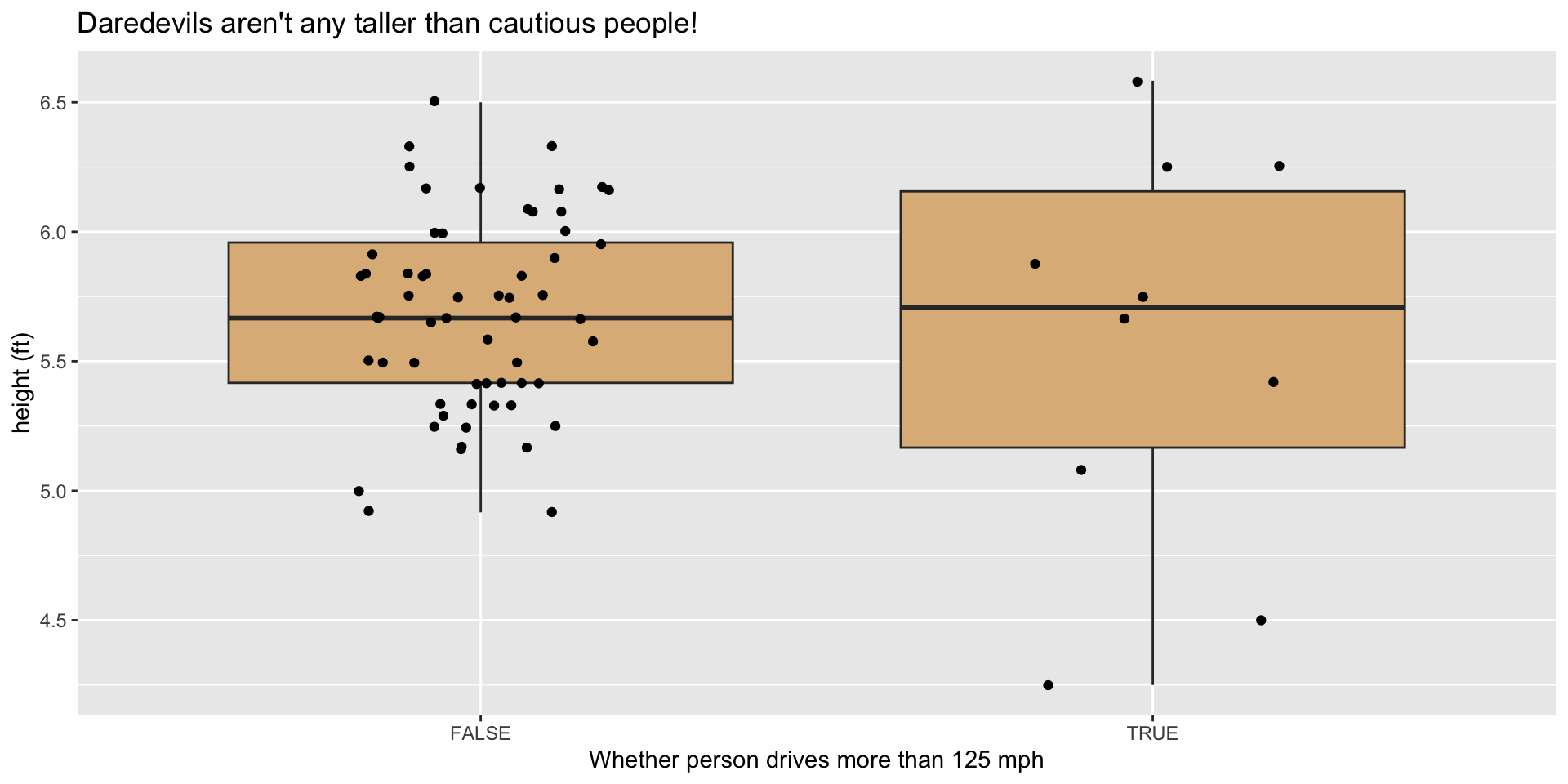
You’re a Daredevil if you go more than 125 mph:
More Than One Variable Transformed
Expand for code
survey |>
mutate(dareDevil = fastest > 125,
height_ft = height / 12) |>
ggplot(aes(x = dareDevil, y = height_ft)) +
geom_boxplot(fill = "burlywood", out.alpha = 0) +
geom_jitter(width = 0.2) +
labs(
x = "Whether person drives more than 125 mph",
y = "height (ft)",
title = "Daredevils aren't any taller than cautious people!"
)
Summarizing, Groups, Arranging
Back to CPS85
Access the CPS85 data in the mosaicData package:
Mean Wage
The mean wage for all the workers:
Mean Wage for Each Sex
Break data into groups according to the values of sex:
More Than One Summary
Five-Number Summary
Summary by Sex
Grouping by More Than One Variable
Expand for code
sector sex n min Q1 median Q3 max
1 const M 20 3.75 7.150 9.750 11.825 15.00
2 sales M 21 3.50 5.560 9.420 12.500 19.98
3 sales F 17 3.35 3.800 4.550 5.650 14.29
4 clerical F 76 3.00 5.100 7.000 9.550 15.03
5 service F 49 1.75 3.750 5.000 8.000 13.12
6 manuf M 44 3.35 6.585 8.945 11.250 22.20
7 prof M 53 5.00 8.000 12.000 16.420 24.98
8 service M 34 2.01 4.150 5.890 8.750 25.00
9 other M 62 2.85 5.250 7.500 11.250 26.00
10 clerical M 21 3.35 6.000 7.690 9.000 12.00
11 manag M 34 1.00 8.800 13.990 18.160 26.29
12 prof F 52 4.35 7.025 10.000 12.275 24.98
13 manag F 21 3.64 6.880 10.000 11.250 44.50
14 manuf F 24 3.00 4.360 4.900 6.050 18.50
15 other F 6 3.75 4.000 5.625 6.880 8.93But …
That table was hard to use. we would like the men and the women next to each other, for each sector.
Solution: arrange()
Expand for code
sector sex n min Q1 median Q3 max
1 clerical F 76 3.00 5.100 7.000 9.550 15.03
2 clerical M 21 3.35 6.000 7.690 9.000 12.00
3 const M 20 3.75 7.150 9.750 11.825 15.00
4 manag F 21 3.64 6.880 10.000 11.250 44.50
5 manag M 34 1.00 8.800 13.990 18.160 26.29
6 manuf F 24 3.00 4.360 4.900 6.050 18.50
7 manuf M 44 3.35 6.585 8.945 11.250 22.20
8 other F 6 3.75 4.000 5.625 6.880 8.93
9 other M 62 2.85 5.250 7.500 11.250 26.00
10 prof F 52 4.35 7.025 10.000 12.275 24.98
11 prof M 53 5.00 8.000 12.000 16.420 24.98
12 sales F 17 3.35 3.800 4.550 5.650 14.29
13 sales M 21 3.50 5.560 9.420 12.500 19.98
14 service F 49 1.75 3.750 5.000 8.000 13.12
15 service M 34 2.01 4.150 5.890 8.750 25.00Saving Output
Table-Display Tips
Quarto
In Quarto documents:
- very small tables (one or two rows) can be printed as is;
- medium tables (3-15 rows, roughly) could be displayed with
knitr::kable(); - larger tables could be displayed with
DT::datatable().
There are many more fun options for table-display; this page has a list.
A Very Small Table
A Medium-Sized Table
| sector | meanWage | n |
|---|---|---|
| const | 9.502000 | 20 |
| sales | 7.592632 | 38 |
| clerical | 7.422577 | 97 |
| service | 6.537470 | 83 |
| manuf | 8.036029 | 68 |
| prof | 11.947429 | 105 |
| other | 8.500588 | 68 |
| manag | 12.704000 | 55 |
Large Tables
Here is the Table
DT Options
You can control many things:
See here to learn more.
Fun Option: reactable()
Expand for code
Learn more about reactable here.
Fun Option: gt()
library(gt)
CPS85 |>
summarize(
n = n(),
median_wage = median(wage),
.by = c(sector, sex)
) |>
filter(
sector %in% c(
"manag", "manuf", "prof"
)
) |>
gt() |>
tab_header(
title = "Wage by Sector and Sex",
subtitle = "Current Population Survey, 1985"
) |>
fmt_currency(
columns = c(median_wage),
currency = "USD"
) |>
tab_source_note(
source_note = md("From table `CPS85` in package [**mosaicData**](https://cran.r-project.org/web/packages/mosaicData/index.html)")
) Learn more about gt here.
| Wage by Sector and Sex | ||
| Three sectors are shown. | ||
| sex | n | median_wage |
|---|---|---|
| manag | ||
| F | 21 | $10.00 |
| M | 34 | $13.99 |
| manuf | ||
| F | 24 | $4.90 |
| M | 44 | $8.95 |
| prof | ||
| F | 52 | $10.00 |
| M | 53 | $12.00 |
From table CPS85 in package mosaicData |
||